
A robots txt file generator is a tool that automatically creates a properly formatted robots.txt file — the small but powerful text file that tells search engine crawlers which pages to visit and which to skip. Getting this file right is one of the most impactful technical SEO steps you can take, and a generator removes the guesswork entirely.
According to Google’s official crawling documentation, the robots.txt protocol has been in use since 1994 and remains a foundational standard for managing how bots interact with your site. Despite its age, many websites still have errors in their robots.txt files that silently damage their rankings.
Fortunately, using the right generator makes the process fast, accurate, and beginner-friendly. In this guide, you will learn exactly how to use one, what directives matter most, and how to avoid the mistakes that trip up even experienced SEOs.
What Is a Robots TXT File Generator?
A robots txt file generator is an online or software-based tool that builds a valid robots.txt file through a guided interface. Instead of writing raw text directives by hand, you fill in fields — such as which bots to target and which paths to block — and the tool outputs a ready-to-upload file.
The Robots Exclusion Standard defines the syntax these files must follow. Even a single formatting error — like a missing space after a directive — can cause crawlers to ignore your rules entirely. A generator eliminates that risk by handling syntax automatically.
In short, these tools democratize technical SEO. You do not need to be a developer to produce a clean, effective file.
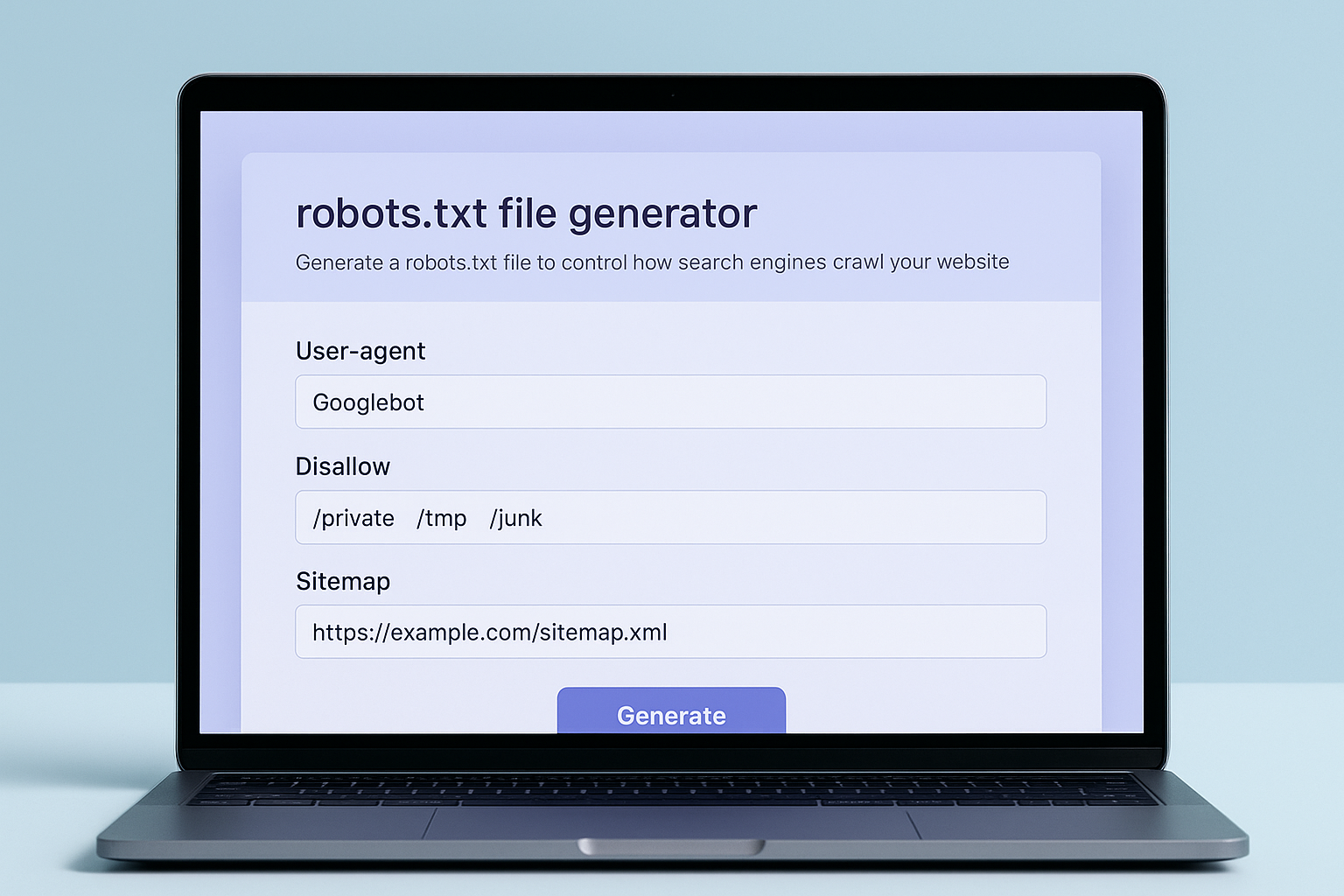
A robots txt file generator simplifies the creation of accurate crawl directives through a guided interface.
Why Your Robots.txt File Matters for SEO
Search engines allocate a limited crawl budget to each website. This budget represents how many pages a bot will process in a given period. Therefore, wasting that budget on admin panels, duplicate pages, or internal search results directly hurts your ability to rank important content.
A well-configured robots.txt file guides bots toward your most valuable pages. As a result, your key landing pages, blog posts, and product pages get crawled and indexed faster. For deeper insight into structuring these files strategically, the guide on creating robots.txt files for SEO success on rankauthority.com covers the full strategic framework.
Furthermore, AI-powered crawlers — including those powering Google’s AI Overviews and tools like ChatGPT — also respect robots.txt rules. Blocking these bots unintentionally can reduce your content’s visibility in AI-generated answers, which is increasingly where search traffic originates.
Key Directives Every Robots.txt File Should Include
Understanding the core directives helps you make smarter choices in any generator tool. Here are the essential ones:
- User-agent: Specifies which crawler the following rules apply to. Use
*for all bots. - Disallow: Blocks a crawler from accessing a specific path or directory.
- Allow: Explicitly permits access to a path, even within a disallowed directory.
- Sitemap: Points crawlers to your XML sitemap for complete page discovery.
- Crawl-delay: Requests a pause between requests to reduce server load (not supported by all bots).
Most quality generators present these as simple form fields, so you never need to memorize the exact syntax.
How to Create a Robots.txt File Using a Generator
Follow these five steps to produce a clean, effective robots.txt file in under ten minutes.
- Choose a reliable robots txt file generator tool. Select a reputable generator that supports multiple User-agent blocks, Allow and Disallow entries, and a dedicated sitemap field. Avoid tools that produce outdated syntax or lack validation features.
- Define your User-agent targets. Start with a wildcard (
*) block for all crawlers, then add specific blocks for bots like Googlebot or Bingbot if you need tailored rules for each. - Set your Allow and Disallow directives. Block paths such as
/wp-admin/,/cart/, and URL parameter pages. Use Allow rules to carve out exceptions within broader blocked directories. - Add your sitemap URL. Include your XML sitemap at the end using the Sitemap directive. This helps crawlers discover all important pages efficiently, even those buried deep in your site structure.
- Test and upload the generated file. Paste your output into Google Search Console‘s robots.txt tester. Once confirmed error-free, upload the file to your domain’s root directory so it is accessible at
https://yourdomain.com/robots.txt.
After generating your robots.txt file, upload it directly to your domain’s root directory for immediate effect.
Common Mistakes to Avoid When Generating a Robots.txt File
Even with a generator, certain errors are surprisingly common. Knowing them in advance saves you from costly ranking drops.
Blocking Your Entire Site by Accident
The single most dangerous mistake is using Disallow: / under a wildcard User-agent. This blocks every crawler from every page. Consequently, your entire site can disappear from search results within days. Always double-check the Disallow field before saving.
Blocking CSS and JavaScript Files
Google’s crawler renders pages similarly to a browser. Therefore, blocking your CSS or JavaScript directories prevents Googlebot from understanding how your pages look and function. This can negatively affect mobile usability scores and overall ranking signals.
Relying on Robots.txt Alone to Hide Sensitive Pages
A disallowed URL is not hidden — it is simply not crawled. However, if another site links to that URL, Google may still index it. For truly private pages, combine robots.txt with a noindex meta tag or password protection.
For a deeper exploration of these nuances and advanced configuration strategies, the advanced robots.txt configuration guide at rankauthority.com provides detailed examples and edge cases.
Robots.txt and AI Search: What’s Changing
The rise of AI-powered search engines has introduced new crawler types. Google’s AI Overviews, OpenAI’s GPTBot, and Anthropic’s ClaudeBot all send their own crawlers to gather content. Each of these respects the robots.txt standard, meaning your directives directly affect whether your content appears in AI-generated answers.
According to research cited by Wikipedia’s Robots Exclusion Standard article, over 40% of websites block at least one major crawler unintentionally. As AI search grows, that unintentional blocking increasingly means lost visibility in the answers users receive from tools like ChatGPT and Gemini.
If you want your content cited in AI-generated responses, it is worth reviewing how to get cited by AI tools alongside your robots.txt strategy. The complete guide to getting cited by ChatGPT on rankauthority.com covers exactly that intersection.
Furthermore, platforms like rankauthority.com offer automated GEO and AEO optimization tools that work alongside your technical SEO setup — including robots.txt management — to maximize visibility across both traditional and AI-powered search environments.
Best Practices for an SEO-Optimized Robots.txt File
In addition to avoiding mistakes, applying these best practices ensures your robots.txt file actively supports your SEO strategy:
- Always include your sitemap URL — it helps crawlers find pages they might otherwise miss.
- Keep the file concise — Google processes up to 500 KiB, but a shorter file is easier to audit and maintain.
- Use specific paths — block
/wp-admin/rather than broad directories that might catch important pages. - Audit regularly — revisit your robots.txt every time your site structure changes significantly.
- Test after every change — use Google Search Console’s tester to verify that critical pages remain accessible.
Similarly, if you use AI-generated content on your site, consider how crawlers evaluate that content. The guide to detecting AI-generated content on rankauthority.com explains how detection tools work and why content quality signals matter to crawlers.
Frequently Asked Questions About Robots TXT File Generator
What is a robots txt file generator?
A robots txt file generator is a tool that creates a properly formatted robots.txt file for your website automatically. It guides you through setting crawl rules without requiring manual code knowledge.
Why does every website need a robots.txt file?
A robots.txt file tells search engine crawlers which pages to access and which to skip. Without one, bots may waste crawl budget on low-value pages, reducing overall SEO performance.
Does a robots.txt file block pages from Google’s index?
Disallowing a URL in robots.txt prevents crawling but does not guarantee removal from the index. Google can still index a disallowed URL if other sites link to it. Use noindex meta tags for guaranteed exclusion.
How do I add a sitemap to my robots.txt file?
Add a Sitemap directive at the bottom of your robots.txt file using the format: Sitemap: https://yourdomain.com/sitemap.xml. Most robots txt file generators include this field automatically.
What is the difference between Allow and Disallow in robots.txt?
Disallow prevents a crawler from accessing a specified path, while Allow explicitly permits access even within a disallowed directory. Allow takes precedence when rules conflict.
Can I block specific bots with a robots.txt file?
Yes. Use a separate User-agent block naming the specific bot, such as Bingbot or AhrefsBot, followed by the desired Disallow rules. Different bots can receive entirely different instructions.
How large can a robots.txt file be?
Google supports robots.txt files up to 500 kibibytes (KiB) in size. Rules beyond that limit are ignored, so keep your file concise and well-organized.
Where should the robots.txt file be placed on my website?
The robots.txt file must be placed in the root directory of your domain, accessible at https://yourdomain.com/robots.txt. Placing it in a subdirectory will not work.
What common mistakes should I avoid in a robots.txt file?
Common mistakes include accidentally blocking CSS and JavaScript files, disallowing your entire site with Disallow: /, and forgetting to add your sitemap URL. Always test your file after creation.
How can I test my robots.txt file for errors?
Google Search Console includes a robots.txt tester that shows which URLs are blocked or allowed. You can also use third-party validators to check syntax before publishing.
Does robots.txt affect AI crawlers and answer engines?
Yes. AI crawlers like GPTBot and Google’s AI Overview bots respect robots.txt directives. Blocking them unintentionally prevents your content from appearing in AI-generated answers, which increasingly drives search traffic.
How often should I update my robots.txt file?
Update your robots.txt file whenever your site structure changes significantly or when you add new sections to block or allow. Regular audits every few months are a solid best practice.
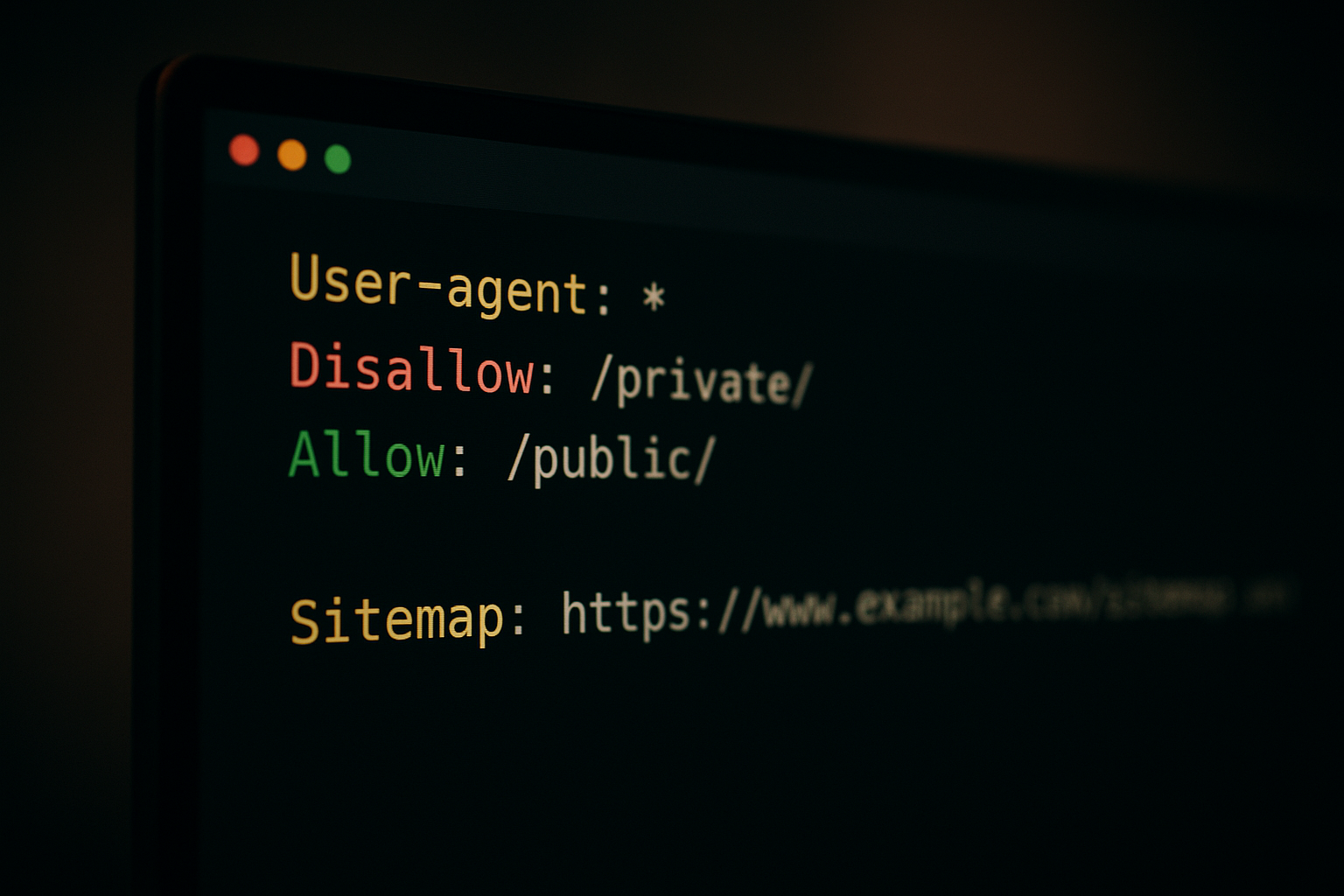
A well-structured robots.txt file uses clear directives that search engine crawlers can parse instantly.
Conclusion: Start With the Right Tool
Using a robots txt file generator is the fastest and most reliable way to produce a crawl-directive file that genuinely supports your SEO goals. Rather than risking syntax errors or accidentally blocking critical pages, a good generator walks you through every decision and outputs clean, valid code in seconds.
In summary, the key takeaways are: place your file in the root directory, always include your sitemap, test before uploading, and revisit your configuration whenever your site structure evolves. Additionally, keep AI crawlers in mind — your robots.txt file now shapes your visibility in AI-powered search as much as in traditional results.
For a complete optimization strategy that goes beyond robots.txt — covering AI search, answer engine visibility, and automated SEO — explore what rankauthority.com offers through its 1-Click AI AutoPilot platform. Technical foundations like a well-crafted robots.txt file, combined with intelligent automation, give your site the best possible chance of ranking in every search environment.
