
Quick Answer: The basics of search engine technology refer to the three fundamental processes every search engine uses — crawling, indexing, and ranking — to discover web pages, store their content, and deliver the most relevant results to users.
Understanding the basics of search engine technology is the single most important foundation for anyone who wants to build a website that attracts real, lasting organic traffic. Whether you are a business owner, a content creator, or an aspiring SEO professional, knowing how search engines discover, evaluate, and rank web pages gives you a decisive edge. This guide breaks down every core concept in plain language — no jargon, no fluff — so you can start applying these principles immediately.
What Is a Search Engine? The Basics Explained
A search engine is a software system designed to carry out web searches — that is, to search the World Wide Web in a systematic way for particular information specified in a text-based query. The search engine collects information from across the internet, organizes it into a massive database called an index, and then retrieves and ranks the most relevant results whenever a user submits a search.
According to Wikipedia’s entry on web search engines, the first tools of this kind appeared in the early 1990s, and today Google alone processes more than 8.5 billion searches per day. The dominant players — Google, Bing, and others — all follow the same fundamental three-stage architecture.
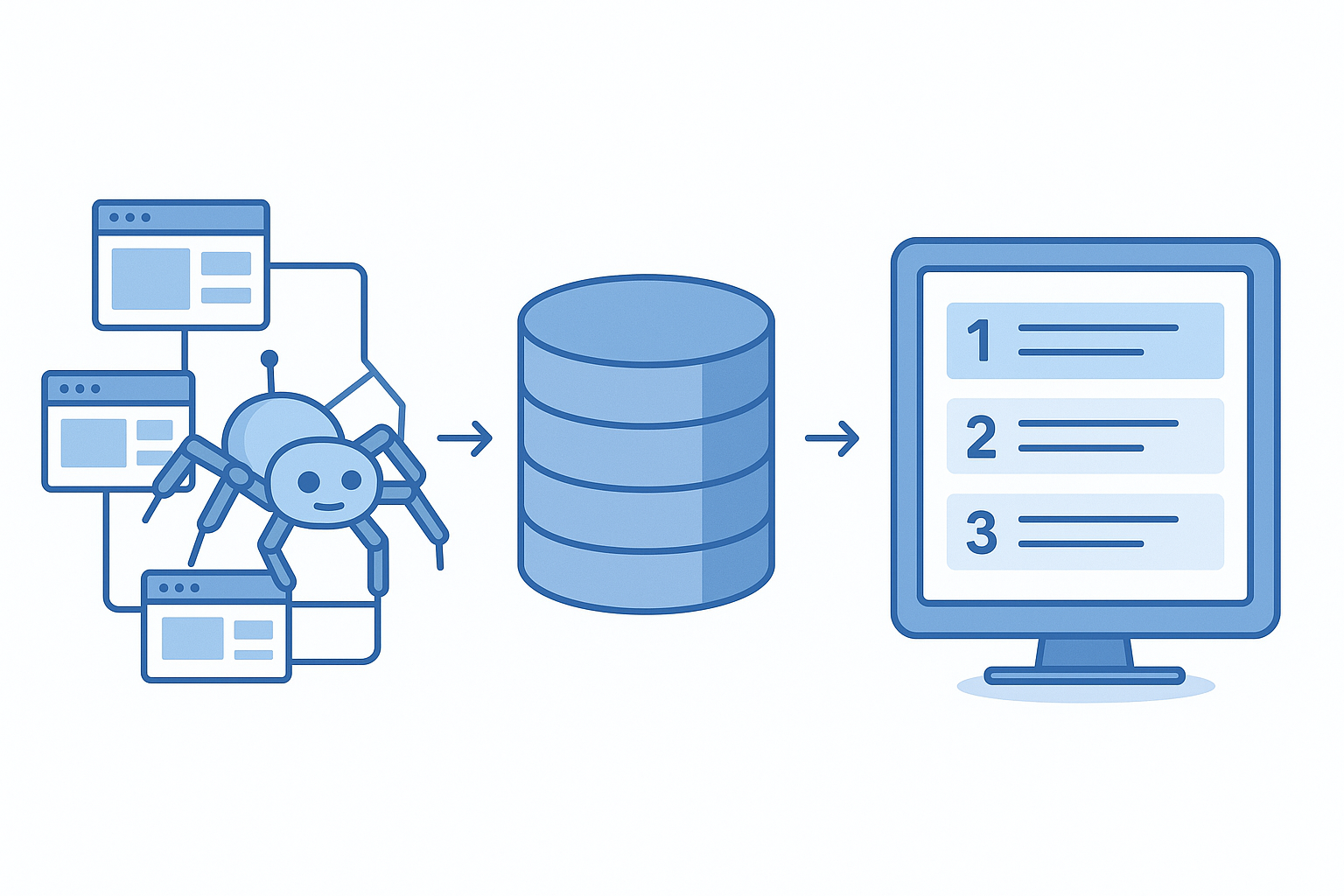
The three core stages of a search engine — crawling, indexing, and ranking — form the foundation of every SEO strategy.
Stage 1: Crawling — How Search Engines Discover Pages
Crawling is the discovery phase. Search engines deploy automated programs called crawlers, spiders, or bots — Google’s is famously known as Googlebot — that continuously browse the web by following hyperlinks from one page to another. Every time a crawler visits a page, it reads the content, records the links it finds, and queues those linked pages for future visits.
The crawler starts from a set of known URLs (called a seed list) and expands outward. This is why internal linking and submitting a sitemap to Google Search Console are critical practices — they help crawlers find all your important pages faster and more reliably.
Key Crawling Factors
- Crawl budget: The number of pages a crawler will visit on your site within a given timeframe.
- robots.txt: A file that tells crawlers which pages or sections they are allowed to access.
- XML sitemaps: A roadmap of your site’s pages that you submit directly to search engines.
- Internal links: Connections between your own pages that guide crawlers through your content hierarchy.
Stage 2: Indexing — How Search Engines Store Information
Once a crawler has visited a page, the search engine processes and stores the information in its index — a colossal database containing information about hundreds of billions of web pages. Think of the index as a library catalogue: when you search for something, the engine doesn’t re-scan the entire web in real time; it retrieves pre-stored data from this catalogue.
During indexing, the engine analyzes the page’s text, images, videos, and metadata. It identifies the main topics, detects the language, notes the last modification date, and records the page’s relationship to other documents. Pages that cannot be crawled — due to broken links, login walls, or blocking directives — will never be indexed and therefore will never appear in search results.

The search engine index functions like a vast digital library — every page that gets indexed becomes retrievable in milliseconds.
Stage 3: Ranking — How Search Engines Order Results
Ranking is where search engines determine which indexed pages are most relevant and authoritative for a specific query, then display them in order. Google’s algorithm evaluates over 200 ranking signals simultaneously. While the full list is proprietary, the most well-established factors include:
Content Signals
- Keyword relevance
- Content depth and quality
- Search intent match
- E-E-A-T (Experience, Expertise, Authoritativeness, Trust)
Technical Signals
- Page speed and Core Web Vitals
- Mobile-friendliness
- HTTPS security
- Structured data markup
Authority Signals
- Backlink quantity and quality
- Domain authority
- Link anchor text relevance
- Brand mentions and citations
User Signals
- Click-through rate (CTR)
- Dwell time on page
- Bounce rate
- Pogo-sticking behavior
Organic vs. Paid Search Results
Search engine results pages (SERPs) contain two types of results. Organic results are earned entirely through SEO — no payment is involved. Their position is determined solely by the ranking algorithm. Paid results (typically labeled “Sponsored”) are purchased through platforms like Google Ads on a cost-per-click (CPC) basis.
For long-term, sustainable growth, organic traffic is far more valuable. Studies consistently show that organic results receive the majority of clicks — often more than 70% — because users trust them more than advertisements. This is precisely why mastering the basics of search engine optimization is a high-return investment for any website.
How to Optimize Your Site: 5 Actionable Steps
Now that you understand the three core stages, here is how to apply them to your own website:
-
1
Conduct Keyword Research
Identify the exact terms your audience searches for. Focus on keywords with clear intent and realistic competition levels for your site’s current authority.
-
2
Optimize On-Page Content
Place your target keyword in the title tag, first paragraph, at least one heading, and naturally throughout the body. Prioritize depth, accuracy, and genuine usefulness.
-
3
Improve Technical SEO
Ensure fast load times, mobile responsiveness, HTTPS, and a clean site architecture. Fix crawl errors and submit your XML sitemap to Google Search Console.
-
4
Build Quality Backlinks
Earn links from relevant, authoritative websites through original research, guest posts, and digital PR. A single high-quality backlink outweighs dozens of low-quality ones.
-
5
Monitor and Refine
Track rankings, organic traffic, and CTR using Google Search Console and analytics tools. Use the data to update existing content and identify new opportunities.
Frequently Asked Questions

Applying SEO knowledge in practice — understanding search results is the first step toward improving your rankings.
Going Deeper: Resources to Advance Your SEO Knowledge
The concepts covered here are the foundation, but SEO is a deep discipline that rewards ongoing learning. For practical, up-to-date guidance on applying these search engine fundamentals to real-world campaigns, RankAuthority offers in-depth resources covering everything from technical audits to content strategy and link building.
As you grow more confident with the core mechanics, you will want to explore advanced topics such as semantic search, entity optimization, Core Web Vitals, and the role of artificial intelligence in modern ranking algorithms. Each of these builds directly on the three-stage crawl-index-rank model you now understand.
Conclusion
Mastering the basics of search engine technology — crawling, indexing, and ranking — gives you the mental model to make smarter decisions about every aspect of your website. When you understand what search engines are looking for, you stop guessing and start building content and technical structures that earn visibility. Apply the five-step optimization framework above, track your results consistently, and use trusted resources like RankAuthority to stay current as algorithms evolve. The fundamentals never change — execution and consistency do.
